kafka生产者原理分析
1. 前言
Apache Kafka® is an event streaming platform
生产者在发送消息到kafka之前,需要经过拦截器(ProducerInterceptors)、序列化器(keySerializer、valueSerializer)、分区器(Partitioner)最后放入消息累加器(RecordAccumulator),由Sender线程发送到kafka集群。
2. 拦截器
责任链模式
1 | |
3. 序列化器
- KeySerializer
- ValueSerializer
注意:生产者和消费者配置的序列化方式必须一致。之前cacs由于生产者用json序列化,消费者用string反序列化,导致内容前后多了双引号。
4. 分区器
分三种情况:
优先使用指定的分区。
1
2
3
4
5
6
7
8
9
10
11
12/**
* computes partition for given record.
* if the record has partition returns the value otherwise
* calls configured partitioner class to compute the partition.
*/
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}注意:需要关注人为的分区策略是否可以均匀的将消息分配到分区里。
否则使用序列化后的key对分区数取模。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param numPartitions The number of partitions of the given {@code topic}
* @param key The key to partition on (or null if no key)
* @param keyBytes serialized key to partition on (or null if no key)
* @param value The value to partition on or null
* @param valueBytes serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,
int numPartitions) {
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
注意:是否会导致计算分区不均匀?
- 如果key为空,就用粘性分区
StickyPartitionCache。
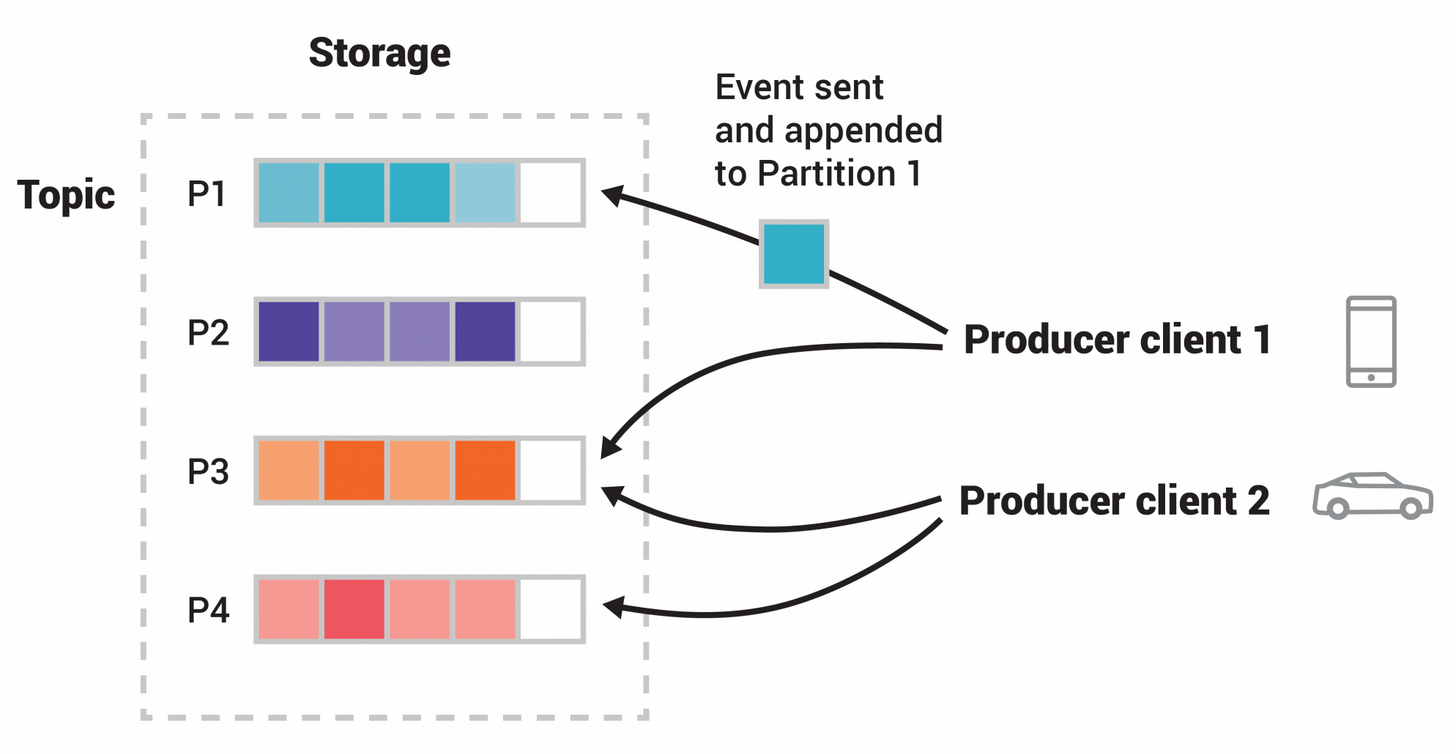
5. RecordAccumulator
采用的是双端队列Deque来存储消息,由Sender线程异步的发送到kafka集群。
Deque(double-ended queue,双端队列)是一种具有队列和栈的性质的数据结构。双端队列中的元素可以从两端弹出。
步骤:
- 根据分区拿到Deque,没有就创建新的Deque
- 对dq加锁
- tryAppend()
- 解锁
1 | |
6. 架构
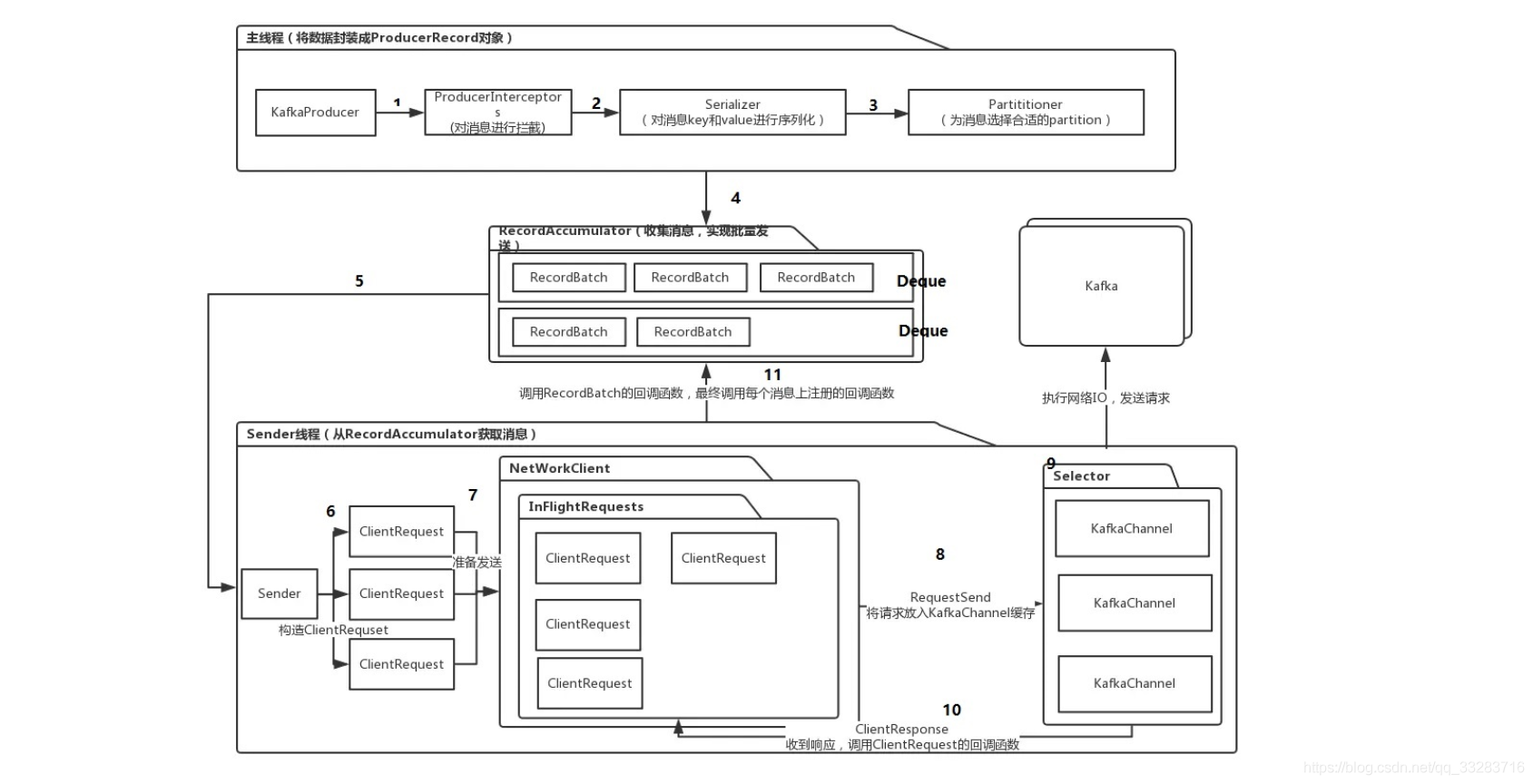
- 用户组装消息:ProducerRecord
- ProducerInterceptors对消息进行拦截。
- Serializer对消息的key和value进行序列化
- Partitioner为消息选择合适的Partition
- RecordAccumulator收集消息,放入双端队列(Deque),以实现批量发送(MemoryRecords)
- Sender从RecordAccumulator获取消息,将发往不同broker的消息分组打包,以减少网络IO
- 构造ClientRequest
- 将ClientRequest交给NetworkClient,准备发送
- NetworkClient将请求放入KafkaChannel的缓存
- 执行网络I/O,发送请求
- 收到响应,调用Client Request的回调函数
- 调用RecordBatch的回调函数,最终调用每个消息注册的回调函数
消息发送的过程中,设计两个线程协同工作。主线程首先将业务数据封装成ProducerRecord对象,之后调用send方法将消息放入RecordAccumulator中暂存,Sender线程负责将消息信息构成请求,并最终执行网络I/O的线程,他从Record Accumulator中取出消息并批量发送出去。
7. 请求数据结构
kafka-clients-2.6.0.jar!/common/message/ProduceRequest.json
1 | |
8. 问题
8.1. 为什么用双端队列
在Sender线程里,将失败的时候重新放入队列
1 | |
8.2. kafka如何保证消息的顺序性
kafka只保证分区内消息的顺序性。
- 生产者端,每个分区使用一个Deque,使用了锁保证了队列顺序性。
- 服务端,使用顺序存储
- 消费者,一个分区在同一个Group内只能被一个消费者订阅。
9. 扩展
ConcurrentHashMap 分段锁 VS RecordAccumulator